Casi que no comento nada sobre qué son y esas cosas que se suelen poner de relleno al principio de las publicaciones para retener más a la gente, a estas alturas no creo que haya mucha gente que no haya oído “IA” o “red neuronal” más de 20 veces.
No tengo anuncios así que no gano nada si me lees durante más tiempo y cuanto menos te lleve, más tiempo tienes para otras cosas.
Ah, una cosa más antes de empezar, a los “modelos grandes de lenguaje” les voy a llamar LLMs, por sus siglas en inglés, por comodidad, porque nunca he escuchado a nadie usar siglas en castellano y ya que hay “un estándar” pues lo uso (desarrollo abajo lo que son, por ahora sigue leyendo). Usaré IAs y LLMs entremezclados, pero casi siempre me referiré a los modelos de lenguaje.
Ahora sí.
Mi punto
Evidentemente las IAs son herramientas muy útiles, especialmente usadas en ciertos campos en las que se puedan emplear para tomar decisiones en aspectos difíciles de detectar para un ser humano, o para emplearlas como modelos y poder predecir valores.
Pero esto son más bien las IAs “tradicionales”, me refiero, no es la tecnología de la que está hablando todo el mundo todos los días (muy a mi pesar), ese puesto se lo llevan los LLMs, cosas como Claude, los distintos GPT y la multitud de modelos abiertos que existen (ejem ejem “““OpenAI””” ejem ejem).
No hay nada de malo en sí mismo en estos modelos, son una herramienta más que tiene la ventaja de ser accesible usando solo lenguaje natural, sin tener que darle datos codificados de ninguna manera concreta ni buscar empleando palabras clave ni tener respuestas que son números decimales, por decir algo.
Este post viene de alguien que lleva usando GitHub copilot desde la beta gratuita, que ha hecho algún proyecto casi exclusivamente usando IAs y que está en un punto de más odio que amor.
Empiezo por lo malo:
Las pegas
El problema que le veo es, por un lado, la eficiencia (energética principalmente), la calidad de las respuestas y la dependencia a los modelos.
Eficiencia de los LLMS
Energética
El primer factor y uno de los más grandes es el tema energético. Los LLMs consumen cantidades absolutamente descomunales de energía para responder a las preguntas más simples que se te ocurran. Son redes enormes con cantidades muy grandes de valores que tener en memoria (consume energía y requiere componentes caros y difíciles de refrigerar) y que (normalmente) activan todas las partes de la red para todas las consultas1.
Hace no mucho, en un vídeo comentaban que una consulta del “modelo de razonamiento” más avanzado de OpenAI (segunda mención y ninguna buena xd) equivalía en emisiones de CO2 a 5 depósitos de gasolina, que, en caso de ser cierto, es una absoluta barbaridad y completamente insostenible. Si encuentro la fuente la añadiré también, que no me gusta dejar cosas sin documentar.
De uso
Por otro lado, me preocupa la eficiencia al usarlos, ahora se está normalizando el hacerle una consulta y esperar pacientemente a que devuelva una respuesta no muy buena, y a partir de ahí ir llevando al modelo a que te responda lo que buscabas en un principio. En vez de buscar la información en un motor de búsqueda hecho específicamente para encontrar información en base a pequeñas “pistas” que obtiene con lo que buscas, lo que es cada vez más habitual es buscar esa información en los pesos de la red como quien dice.
Y sí, sé que si buscas una respuesta rápida y concisa es muy útil y probablemente más rápido que un buscador, pero muchos usos no son ese, y por otro lado tampoco puedes tener confianza completa en la respuesta, pero eso lo desarrollo más adelante.
Soy consciente de que existen servicios que integran los LLMs en programas que los hacen más prácticos (los LLMs, los programas no son mejores por tener un “asistente” que no sabe contar las Rs en “strawberry”2)
Calidad de las respuestas
A estas alturas ya se sabe bastante, pero las respuestas de un LLM no son muy precisas exactamente.
Por lo general responden decentemente bien, es lo que se consigue prediciendo la siguiente palabra de una frase, pero en cuanto la complejidad de la pregunta aumenta y no se le pide conocimiento que haya visto previamente, sino una versión específica de algo que estás haciendo nuevo, muchas veces es incapaz de generar una buena respuesta ni a la primera, ni a la segunda ni tras varios intentos.
Este aspecto se desarrolla más en este vídeo:
También existen las alucinaciones, cuando se inventa completamente la respuesta juntando palabras que gramaticalmente son correctas y forman frases que podrían ser ciertas pero en realidad no lo son.
En el peor de los casos generará una respuesta a simple vista razonable pero completamente falsa.
Enlazando esto con el punto anterior, cada respuesta inapropiada implica que todo el consumo energético necesario para generarla es inútil y “se tira a la basura” porque no resuelve la consulta inicial e implica otra petición más con su correspondiente coste.
Otra cosa a tener en cuenta es que las respuestas son por la propia definición del modelo mediocres. Los LLMs van concatenando la mejor palabra para continuar la serie una detrás de otra, pero su criterio para elegir la mejor en cada caso se basa en escoger la palabra con mayor probabilidad. En caso de que las opciones se distribuyeran bajo una distribución normal, consistiría en tomar la media, que deja nada más y nada menos que un 50% de palabras a su derecha, que serían las opciones de mejores textos, pero más improbables.
Explicabilidad
Las IAs no son explicables.
Nada nuevo, espero.
Existen los “sparse autoencoders” y todo lo que tú quieras, pero no te vas a poner a mirar todos los pesos y a partir de ellos intentar averiguar lo que está haciendo una red neuronal como sí puedes hacer muy fácilmente con cualquier modelo paramétrico “““tradicional”””.
Fin del argumento básicamente, por qué deberías fiarte de lo que dice si, aunque acierte mucho, no sabe decirte por qué?
Cómo vas a seguir esas instrucciones si la única explicación que puedes dar de estarlas siguiendo es “me lo dijo la IA” (y no sabes por qué)?
Habrá casos donde no te importe demasiado, pero no se pueden tomar decisiones importantes que afecten a personas sin motivo aparente.
Dependencia y coste a las personas
El problema serio es cuando se empieza a depender de herramientas externas para el desarrollo propio, especialmente cuando esas herramientas están ligadas a empresas que evidentemente solo buscan beneficios y aún encima las herramientas son tan poco fiables como los LLMs.
Y no me refiero a desarrollo solo en el sentido de la programación, que es en el que me centraré porque existen multitud de herramientas específicas, pero no es el único afectado ni necesariamente el peor.
Depender de herramientas que no controlas es peligroso porque tu progreso está ligado al progreso de esa herramienta, y en caso de que se estanque, puedes encontrarte sin medios para seguir avanzando.
Un síntoma de ser “dependiente” de las IAs es lo que ThePrimeagen llama en sus vídeos “the copilot pause”, la espera de uno o dos segundos después de empezar a escribir una línea de código, pretendiendo que Copilot la autocomplete por ti, aunque sea la línea más simple del mundo.
Es algo especialmente cierto en etapas de aprendizaje, donde usar las IAs para evitar pensar algunas respuestas hace que no se interioricen los conceptos que se trabajan. En en caso de la programación, emplear código hecho por IAs y juntarlo de la mejor manera posible para que funcione crea una aplicación con código que no conoces porque no lo has escrito tú y que tampoco sabes mantener porque no existe ninguna justificación para las decisiones que es necesario tomar cuando se implementa una funcionalidad de una manera concreta.
Considero que pelearse con el código y “perder” horas averiguando cómo hacer que funcione algo en lo que llevas ya un par de días hace que entiendas a fondo cómo funciona el lenguaje o la librería con la que trabajas, leer documentación se está perdiendo y me parece que es la mejor forma de entender cómo funciona algo para poder usarlo con todo su potencial sin las limitaciones de usar una IA como intermediaria.
La programación consiste principalmente en resolver problemas, y la parte más importante al aprender a programar es enfrentarse a esos problemas y poder desarrollar métodos para dividirlos y encontrar soluciones con las restricciones que tengas para cada problema concreto. Usar una IA para que haga la parte difícil de ese proceso, encontrar una solución al problema, boicotea el aprendizaje ya que, sí, has encontrado la solución, pero te has perdido la parte estimulante intermedia de ir encontrando el camino correcto poco a poco, cada nuevo intento con menos errores y más capacidad para encontrarlos.
Además de que un problema en programación normalmente tiene infinidad de soluciones posibles, y el valor de cada una es el razonamiento que hay detrás de ella.
Otra consideración
Esta idea no es mía de todo, pero me pareció razonable y considero que viene a cuento.
Hasta hace nada los modelos más potentes los tenían empresas privadas, y pretenden venderlos como la tecnología que lo hace todo.
Si realmente su tecnología fuese capaz de crear de todo, por qué la estarían vendiendo y no la estarían usando para crear todos los productos posibles?
Como nota graciosa, Anthropic, los creadores de Claude, otro LLM, están pidiendo
que la gente no use IAs en las entrevistas de trabajo.
Un poco irónico, no?
(Que lidien con el problema que han ayudado a crear, no?)
Fuente
(Archivada en Web Archive).
Otro vídeo que he visto entre empezar a escribir el post y publicarlo, que trata también este tema: enlace.
Esto también aplica aunque más de lejos al tema de “la IA nos va a quitar el trabajo”,
como digo justo aquí debajo, los LLMs están muy bien para eliminar las partes repetitivas,
pero eso es lo que lleva ocurriendo con la automatización desde hace bastante más
tiempo de lo que existen las IAs.
Pero bueno, no es el tema de este post.
Mi opinión en eso es que si eres bueno en lo que haces no deberías estar muy preocupado
por las IAs, deberías estar preocupado en seguir siendo bueno.
Lo desarrollo un poco:
Independientemente de lo que ocurra con las IAs ahora, lo deseable sería poder sentirse
capaz de poder hacer cosas, o al menos de intentar hacerlas, con las herramientas
que haya.
Ahora damos por hecho herramientas que al aparecer no fueron bien recibidas solo
por ser nuevas, pero hoy es normal usarlas y hasta raro que no se usen.
Mucha gente aprendió a programar sin ellas y muchos aprenden con ellas, y al final
lo importante no suele ser la herramienta que usas para arreglar el problema, sino
que el problema está arreglado.
Considero que si te preocupas en aprender y en buscarte la vida para aprender, y
encontrar respuestas por tu cuenta, no te costará adaptarte a los problemas que surjan
en el futuro y adaptar tus herramientas a lo que sea que haga falta hacer.
Las partes buenas
Alguna tenían que tener, digo yo.
Creo que resumo todo en un apartado:
Productividad
Contradictorio, verdad?
Programando, los LLMs son extremadamente útiles para escribir “boilerplate”, código repetitivo necesario para funcionar pero que no aporta la funcionalidad en sí. Por ejemplo, en Python cuando creas una clase, son necesarias ciertas definiciones que son siempre idénticas:
class Sedan(Coche):
def __init__(self, puertas: int = 5): # Por ejemplo
super().__init__()
...
Pero esto se soluciona fácilmente con snippets, “automatizaciones” que te autocompletan parte del código cuando pones ciertas palabras clave, útil por ejemplo para:
if __name__ == "__main__":
...
Pero no siempre es una sustitución constante lo que hace falta, como en esos casos. Para soluciones más “dinámicas”, como escribir un algoritmo simple ya existente, la complejidad está “resuelta”, y si conoces el algoritmo, pasarlo a código es más una tarea mecánica que algo que aporte valor en sí mismo.
Para esos casos, usar IAs en los editores de código es súper útil. Ahorras todo el tiempo que dedicas a las tareas “mecánicas” sin perder libertad en el resto.
Pero no hay que dejarse llevar sin más, he restringido bastante ese caso de uso conscientemente, porque ese es el caso para el que considero que realmente aportan valor, usarlas básicamente como autocompletado de código algo más inteligente.
Mantengo mis opiniones anteriores de que consumen demasiada energía y las respuestas son, de primeras, malas, y es necesario revisarlas antes de aceptarlas, igual que no aceptarías código de un becario sin antes repasarlo antes de fiarte de él.
Condiciones
Mi principal condición para todo lo que pongo ahí arriba es la ejecución local de los modelos.
Deepseek ha demostrado hace nada que se pueden ejecutar modelos de lenguaje de mucha potencia con hardware más modesto que las granjas de las grandes empresas. Pero antes de Deepseek ya existían modelos abiertos muy capaces, como llama, mistral y muchos otros.
Existe ollama, un proyecto que te permite usar modelos abiertos
en tu ordenador, y no, no hace falta tener hardware de la NASA.
Cuanto más nueva la gráfica mejor como norma general, pero hay modelos funcionando
incluso en Raspberry Pis!.
Conclusiones
Es una tecnología muy nueva y es difícil medir el uso todavía, y es razonable.
No creo que las IAs se vayan a ir al menos a corto plazo, así que soy de la opinión
de que es mejor entenderlas, saber usarlas y sacarles todo el beneficio posible.
Pero me parece aún más importante recordar que son una herramienta más, igual que
muchas otras, y no tiene que condicionar tu forma de trabajar ni restringir tu avance.
Gracias por leerme!
Hecho con 🖤 por Appu.
Los modelos “Mixture of Experts” (MoE) emplean “pequeñas redes especializadas” en áreas concretas del conocimiento y seleccionan los “expertos” relevantes que emplear en cada consulta y así evitar la sobrecarga de partes de la red que no le aportan información útil (p.ej. usar la “parte de matemáticas” de un LLM para escribir un poema). ↩︎
Hasta hace bastante poco, los GPT eran incapaces de decir con precisión el número de Rs que contiene la palabra “strawberry”, y cuando decía bien cuántas había, le preguntabas dónde y a veces señalaba 4 Rs. De hecho, OpenAI incluyó en su lanzamiento de o1 un ejemplo donde las contaba bien.
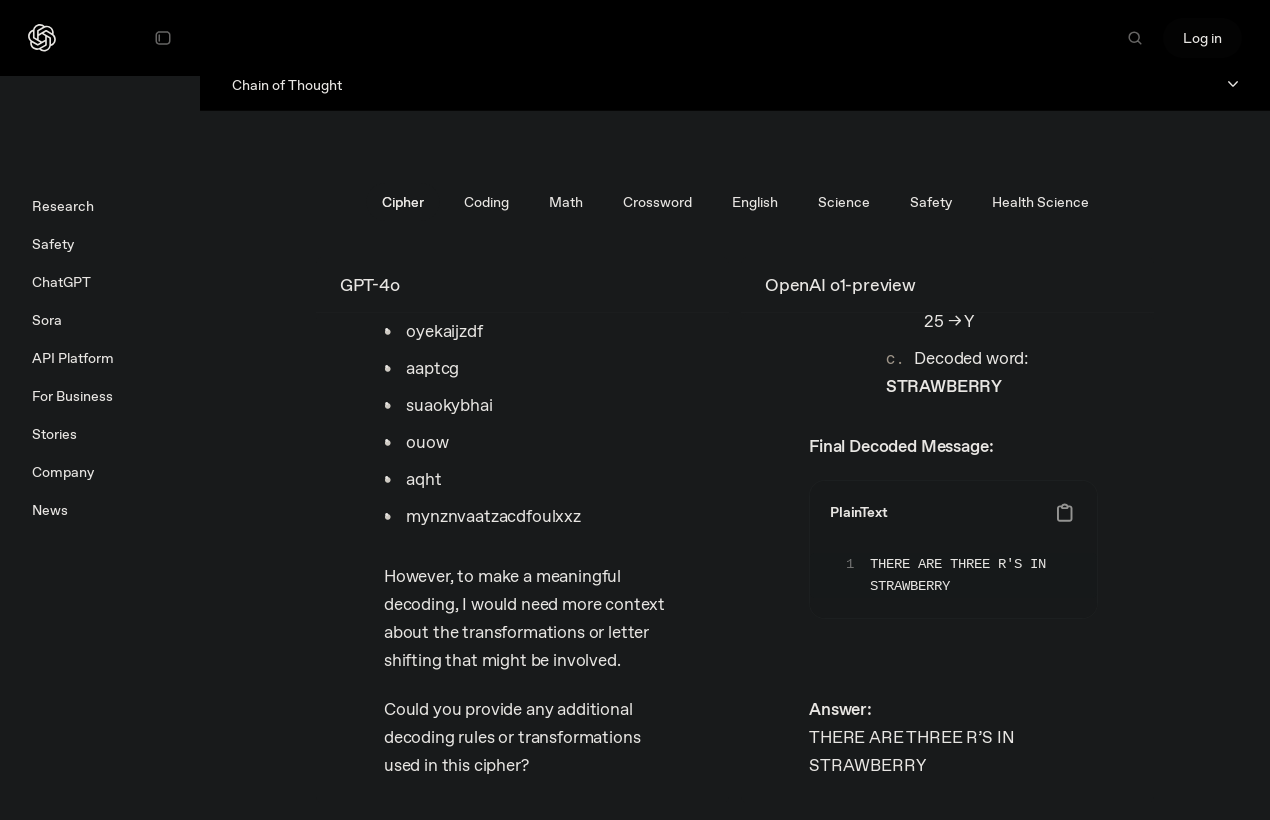 Fuente ↩︎
Fuente ↩︎